
| Dielectric | Lambertian | Metal |
|---|---|---|
 |  |  |
Project Summary
I decided to learn about Ray Tracing after playing “Control” by Remedy Entertainment. Learning how to create a virtual scene using custom vector/ray definition, calculate sphere intersection, and render a baked image was fascinating. Although I’m shifting my focus to other projects emphasizing gameplay and mechanics, I plan to return to this project later and explore more about the graphics pipeline.
Language: C++
Project Repository
My takeaways from this project(so far):
- Learning the basics of how Ray Tracing works!
- How to multi-threading a program in C++
- The programming and learning vector3 class operates under the hood.
- Importing libraries with existing code and using Parrelle Libraries.
- How some functions need to be thread-safe to be utilized properly
Problems encountered
- Circular Dependencies - head files order issue
- int overflow - miscalculations causing corrupted render
- The single-thread render performance is faster than the multi-thread performance on Linux platforms.
- I was so focused on optimizing for speed that I forgot about the image output, causing a corrupted image.
- ‘rand()’ is not thread-safe
Overview - Multi-Threading & Testing Render Speed
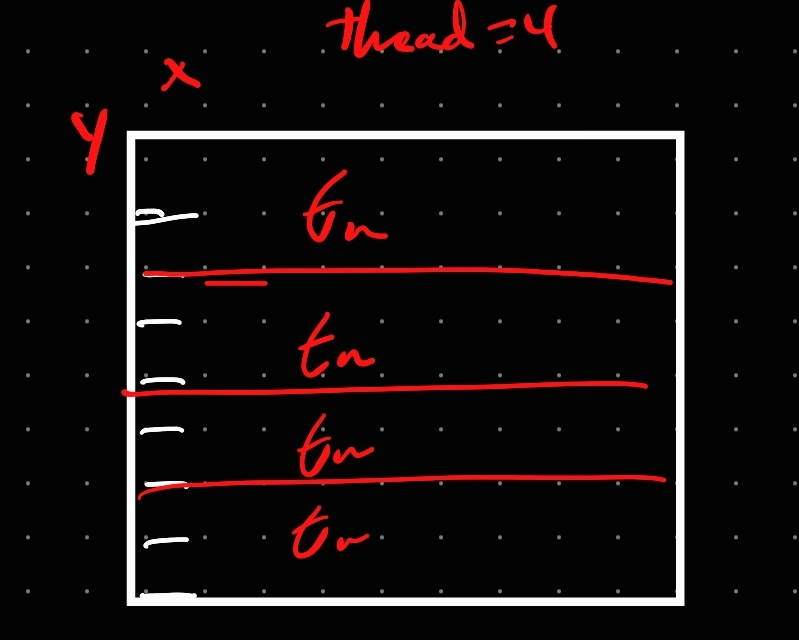
This was the most exciting part of my project. Trying to figure it out took up most of my time. My first approach to this problem was to create my own thread pool. I modeled it after the object pool data structure cause that’s what I use whenever I want to recycle anything within Unity - I wrote object pools before instead of an object, using a thread.
| Mock Up | Result |
|---|---|
 |  |
This worked…. kind of. The image was rendered with a minor corruption on the last line. But the big thing I noticed was that the render time increased.
Pain.
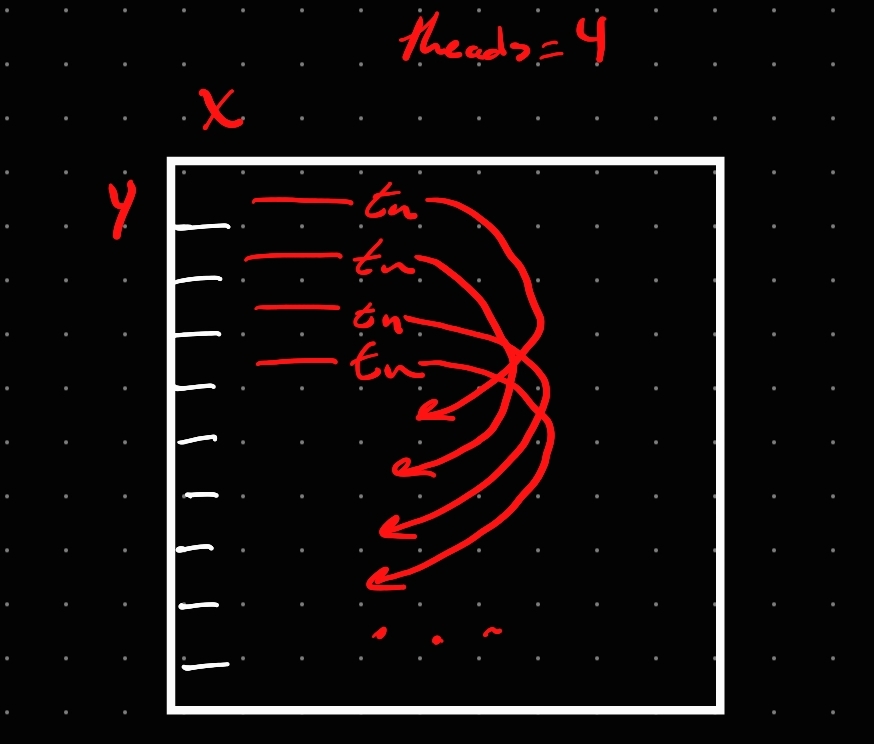
So I went back to the drawing board. With this second method, I decided to base it on the number of threads I had and split the image into sections based on it. That worked, too. Even fixed the image corruption…..Still took longer.
The pain, is building.
After playing around with it, using different compilers, and checking if my code was correct, I decided to test performance on other systems. I had issues on different systems using Linux, but once I tested on Windows and MacOS. It worked ~75% increase. Which was good, but why? Why, on the same system, is Linux performance worse than Windows when running multithreads? At first, with some of the research I came across, it could have been CPU affinity, the Linux scheduling system, or something low-level, which I refused to believe. So, thinking my attempt at programming a multi-threading system was a bust, I decided to implement OpenMP, but the issue persisted.
The Pain is building.

I kept digging, looking for a solution, and then I decided to use an IDE to debug the call stack. I found that the ‘RandomDouble01()’ function was often called. With each core/thread, you’ll have your own stack memory (or its own cache); it was calling that function from the main memory. I ran into a cache coherence issue, which I wouldn’t have known if I was programming on Windows or Mac (Linux for the win!). The solution was to add thread_local to the functions you want to be called locally. I went crazy adding them everywhere, which used randomdouble01(), reducing it to around 300-500ms. Great, until I looked at the photo…

I had to step back. Why not just apply thread_local to RandomDouble01() itself? It still corrupted the image. I was stumped. I returned to the drawing board again and came across the phrase “thread safe”. I looked up if rand() is a thread-safe function; it was not. Using the recommended C++ random function I had seen everywhere, I looked for an alternative to rand() and added thread_local; it worked. Reruning all my tests, seeing the improvements. Even managed to beat out OpenMP with my second method. I also wanted to try more things, such as Tiling. Divide large datasets into smaller tiles, processing one tile pre-thread. Here are the results.
